ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech
Abstract
Denoising Diffusion Probabilistic Models (DDPMs) are emerging in text-to-speech (TTS) synthesis because of their strong capability of generating high-fidelity samples. However, their iterative refinement process in high-dimensional data space results in slow inference speed, which restricts their application in real-time systems. Previous works have explored speeding up by minimizing the number of inference steps but at the cost of sample quality. In this work, to improve the inference speed for DDPM-based TTS model while achieving high sample quality, we propose ResGrad, a lightweight diffusion model which learns to refine the output spectrogram of an existing TTS model (e.g., FastSpeech 2) by predicting the residual between the model output and the corresponding ground-truth speech. ResGrad has several advantages: 1) Compare with other acceleration methods for DDPM which need to synthesize speech from scratch, ResGrad reduces the complexity of task by changing the generation target from ground-truth mel-spectrogram to the residual, resulting into a more lightweight model and thus a smaller real-time factor. 2) ResGrad is employed in the inference process of the existing TTS model in a plug-and-play way, without re-training this model. We verify ResGrad on the single-speaker dataset LJSpeech and two more challenging datasets with multiple speakers (LibriTTS) and high sampling rate (VCTK). Experimental results show that in comparison with other speed-up methods of DDPMs: 1) ResGrad achieves better sample quality with the same inference speed measured by real-time factor; 2) with similar speech quality, ResGrad synthesizes speech faster than baseline methods by more than 10 times.
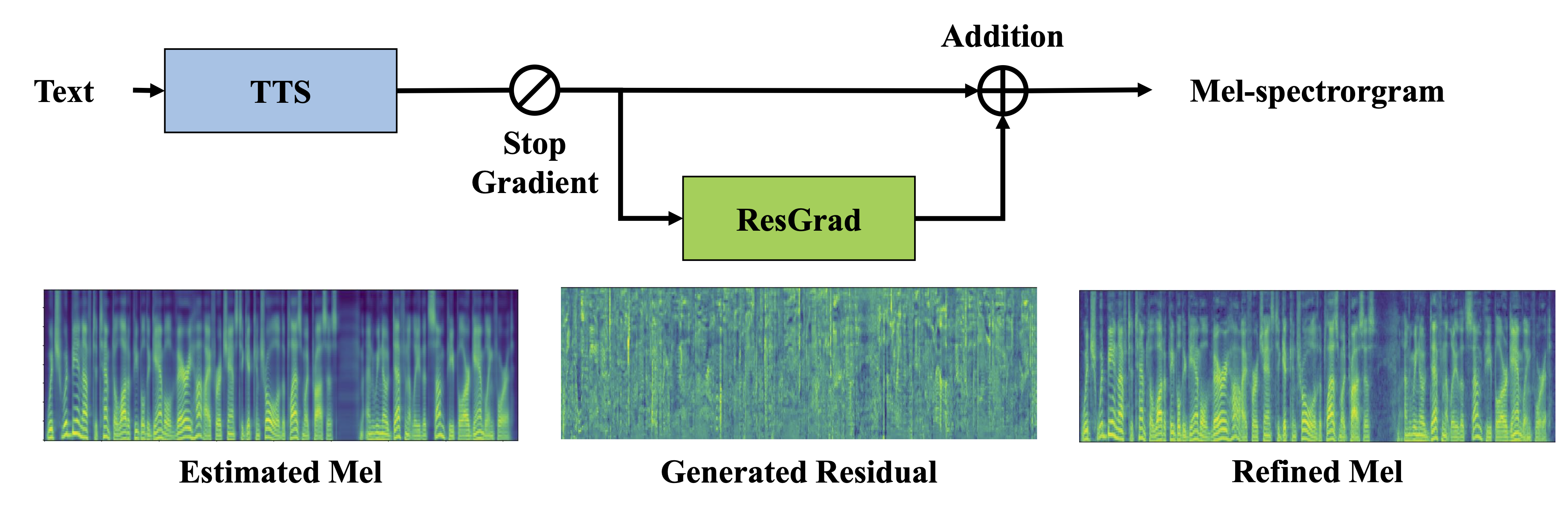
Figure 1: Illustration of ResGrad. ResGrad first predicts the residual between the mel-spectrogram estimated
by an existing TTS model and the ground-truth mel-spectrogram, and then adds the residual to the estimated
mel-spectrogram to get the refined mel-spectrogram.
Audio Samples
Our method is shown in Figure 1. The below audio samples show the comparison between Recordings, ground-truth (GT) mel + Vocoder, FastSpeech 2, DiffGAN-TTS, DiffSpeech, ProDiff, GradTTS, ResGrad-4 (Our method), and ResGrad-50 (Our method). Three samples are randomly selected from the test dataset of LJSpeech, LibriTTS, and VCTK. Details are illustrated as follows:
The number of inference steps used by diffusion models is shown behind the name of models. For example, ResGrad-4 stands for ResGrad with 4 inference steps. But FastSpeech 2 is a model name instead of denoting the number of inference steps.
For each dataset, the inference speed measured by the real-time factor (RTF) is shown in the brackets of the first case.
In order to improve the inference speed at each sampling step, ResGrad uses the same U-Net architecture in GradTTS but with twice fewer channels to reduce the model size (2.0M in ResGrad vs 7.6M in GradTTS).
LJSpeech: A dataset contains the recordings from a female speaker at a sampling rate of 22.05kHz.
Sample 1: Printing, then, for our purpose, may be considered as the art of making books by means of movable types.
Recordings
GT mel + Vocoder
FastSpeech 2 (RTF: 0.003)
ProDiff (0.033)
DiffGAN-TTS (0.009)
ResGrad-4 (0.018)
DiffSpeech-71 (0.182)
GradTTS-50 (0.193)
ResGrad-50 (0.169)
Sample 2: And it was a matter of course that in the Middle Ages, when the craftsmen took care that beautiful form should always be a part of their productions whatever they were,
Recordings
GT mel + Vocoder
FastSpeech 2
ProDiff
DiffGAN-TTS
ResGrad-4
DiffSpeech-71
GradTTS-50
ResGrad-50
Sample 3: produced the block books, which were the immediate predecessors of the true printed book,
Recordings
GT mel + Vocoder
FastSpeech 2
ProDiff
DiffGAN-TTS
ResGrad-4
DiffSpeech-71
GradTTS-50
ResGrad-50
LibriTTS: A dataset contains the recordings from 1046 speakers at a sampling rate of 24kHz.
Sample 1: An old greyhound will trust the more fatiguing part of the chace to the younger, and will place himself so as to meet the hare in her doubles; nor are the conjectures, which he forms on this occasion, founded in any thing but his observation and experience.
Recordings
GT mel + Vocoder
FastSpeech 2 (RTF: 0.003)
ProDiff (0.061)
GradTTS-4 (0.025)
ResGrad-4 (0.020)
DiffSpeech-71 (0.263)
GradTTS-50 (0.259)
ResGrad-50 (0.223)
Sample 2: The one without the other creates a lack of mental balance which is the most favorable condition for a pathological disturbance.
Recordings
GT mel + Vocoder
FastSpeech 2
ProDiff
GradTTS-4
ResGrad-4
DiffSpeech-71
GradTTS-50
ResGrad-50
Sample 3: "This other package must be the manuscript," said Oxenden, "and it'll tell all about it."
Recordings
GT mel + Vocoder
FastSpeech 2
ProDiff
GradTTS-4
ResGrad-4
DiffSpeech-71
GradTTS-50
ResGrad-50
VCTK: A dataset contains the recordings from 108 speakers at a sampling rate of 48kHz.
Sample 1: We also need a small plastic snake and a big toy frog for the kids.
Recordings
GT mel + Vocoder
FastSpeech 2 (RTF: 0.004)
ProDiff (0.235)
GradTTS-4 (0.028)
ResGrad-4 (0.022)
DiffSpeech-71 (0.857)
GradTTS-50 (0.292)
ResGrad-50 (0.244)
Sample 2: We also need a small plastic snake and a big toy frog for the kids.
Recordings
GT mel + Vocoder
FastSpeech 2
ProDiff
GradTTS-4
ResGrad-4
DiffSpeech-71
GradTTS-50
ResGrad-50
Sample 3: We also need a small plastic snake and a big toy frog for the kids.
Recordings
GT mel + Vocoder
FastSpeech 2
ProDiff
GradTTS-4
ResGrad-4
DiffSpeech-71
GradTTS-50
ResGrad-50
Residual Calculation
The below samples show the comparison between the two residual calculation methods in ResGrad. Three samples are selected from the test dataset of LJSpeech to show the risk of using predicted pitch (ResGrad - pitchGT) instead of ground-truth pitch (ResGrad). In inference stage, 50 steps are used for generation.
Sample 1: And it is worth mention in passing that, as an example of fine typography,
FastSpeech 2
ResGrad
ResGrad - pitchGT
GT mel + Vocoder
The generated residual from ResGrad - pitchGT :
Sample 2: Printing, then, for our purpose, may be considered as the art of making books by means of movable types.
FastSpeech 2
ResGrad
ResGrad - pitchGT
GT mel + Vocoder
The generated residual from ResGrad - pitchGT :
Sample 3: The Middle Ages brought calligraphy to perfection, and it was natural therefore
FastSpeech 2
ResGrad
ResGrad - pitchGT
GT mel + Vocoder
The generated residual from ResGrad - pitchGT :
Residual Prediction
The below samples show the comparison between the two residual prediction methods: ResGrad and ResUNet. Three samples are randomly selected from the test dataset of LibriTTS.
Sample 1: Disturbed by these different reflections; inclining now to one course and then to another, and again recoiling from all, as each successive consideration presented itself to her mind; Rose passed a sleepless and anxious night."
FastSpeech 2
ResGrad-4
ResUNet
GT mel + Vocoder
Sample 2: That means from the start an effort to secure balance between general education and particular development.
FastSpeech 2
ResGrad-4
ResUNet
GT mel + Vocoder
Sample 3: "Grandfather, I would give you my two eyes for your place!" cried Manstin.